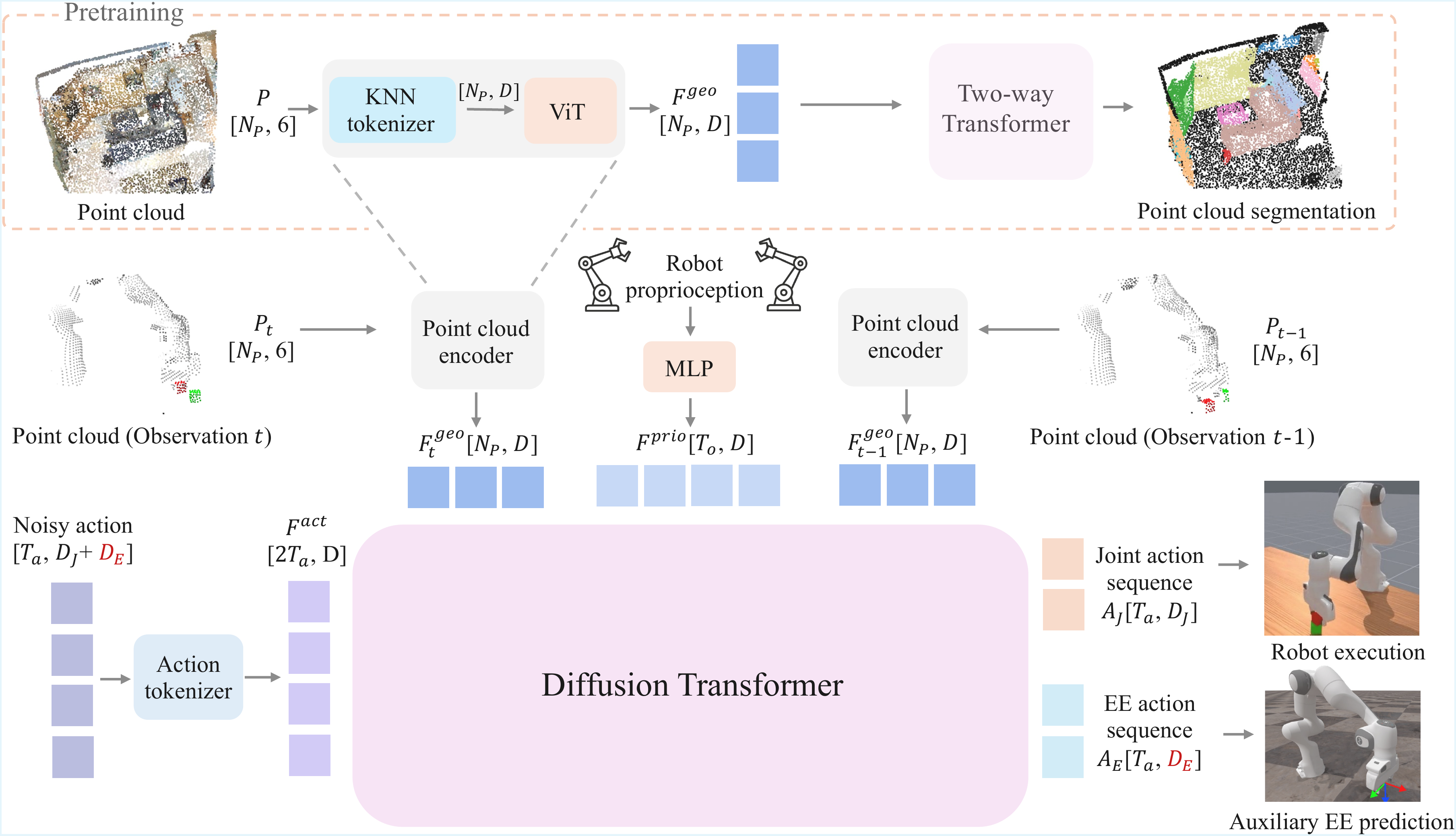
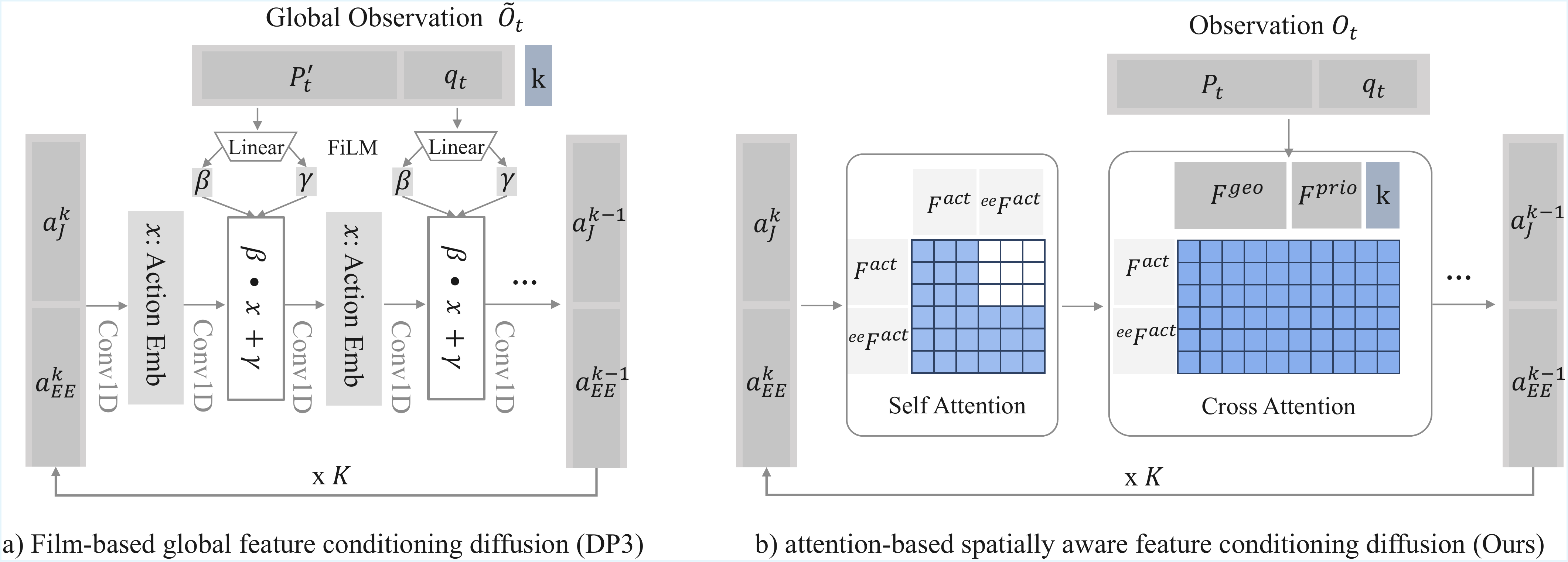
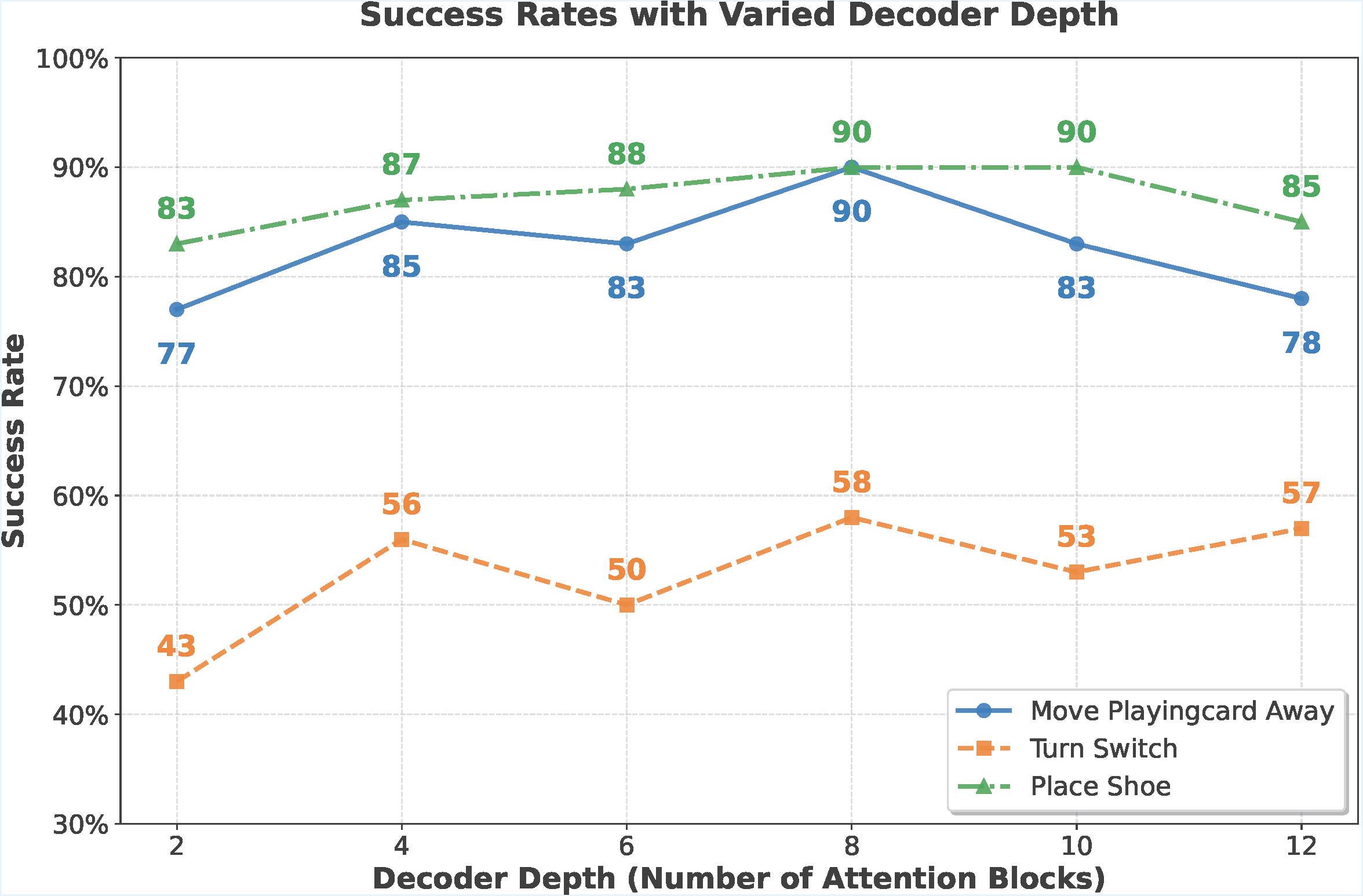
Revisiting 3D Policy Learning
Overcoming the Scaling Paradox: From Batch Norm to Layer Norm
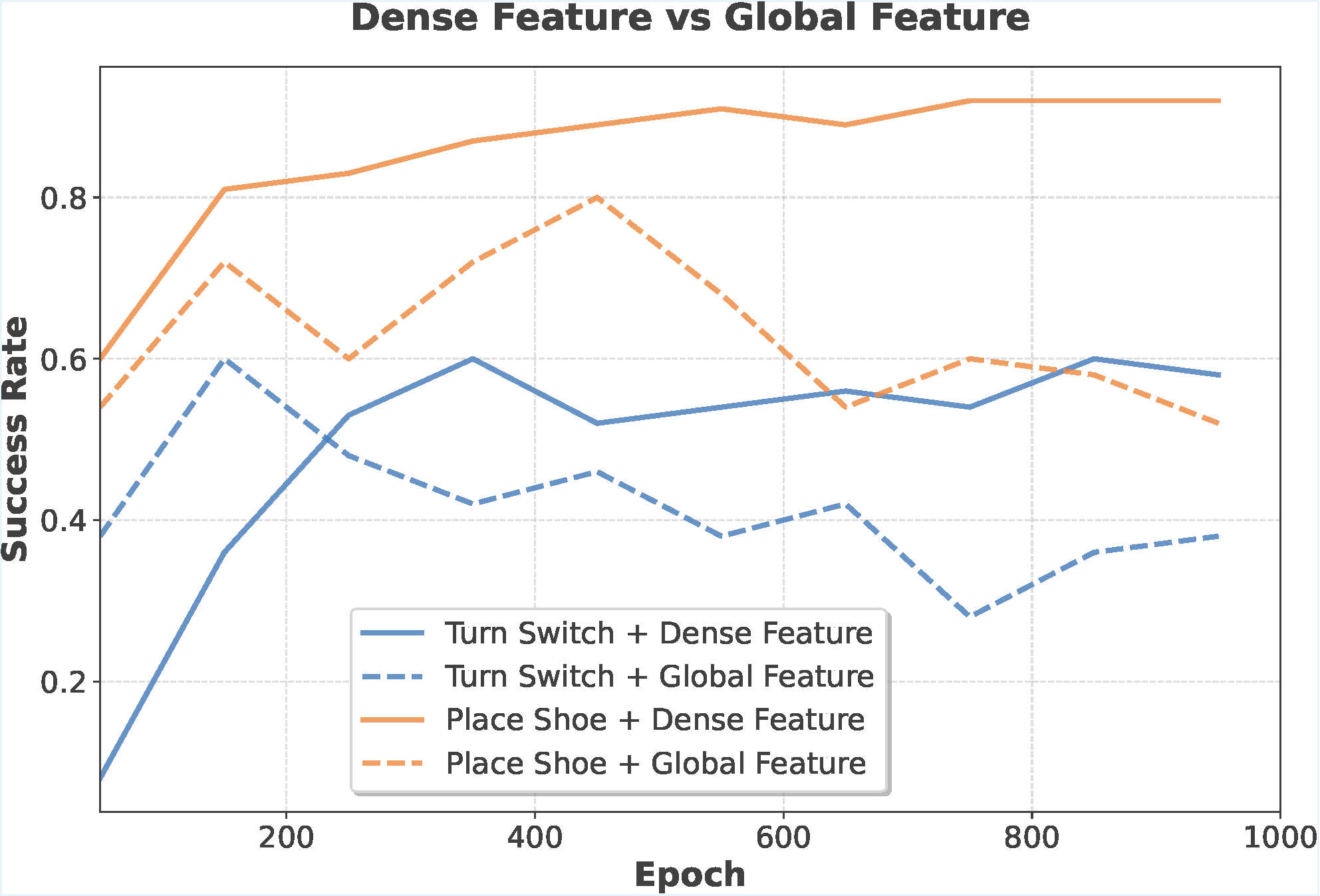
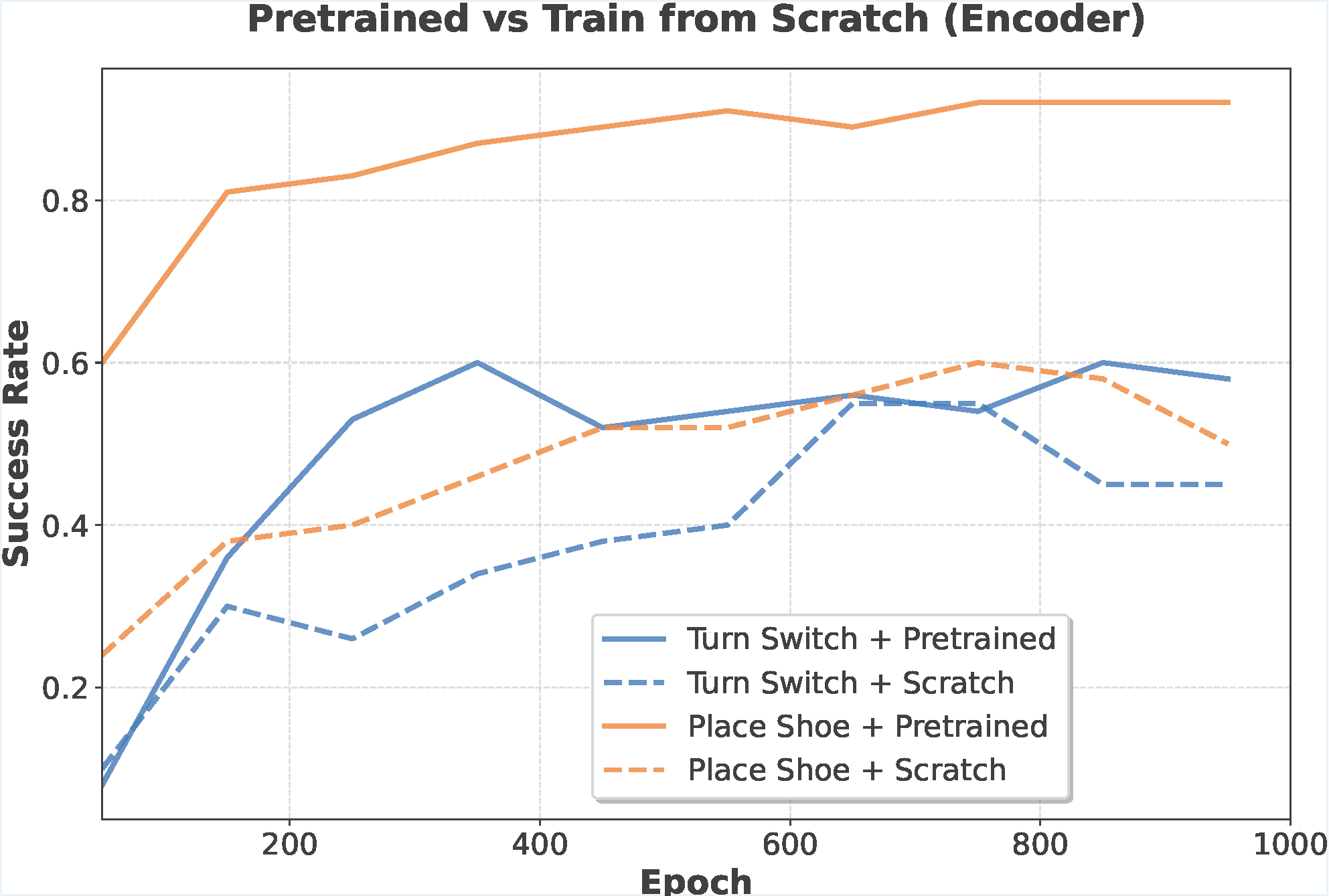
Naively replacing PointNet with a stronger Uni3D encoder causes severe performance degradation. We trace the root cause to Batch Normalization (BN), which struggles under the small batch sizes typical in imitation learning. Switching to Layer Normalization (LN) makes Uni3D not only trainable, but significantly better than PointNet. LN is a more robust default for 3D policies.
BN vs. LN Success Rate (%)
| Method | Beat Hammer | Move Card | Place Shoe | Avg. |
|---|---|---|---|---|
| DP3 (PointNet+BN) | 0 | 3 | 0 | 1.0 |
| DP3 (PointNet+LN) | 79 | 57 | 43 | 59.6 |
| DP3 (Uni3D+BN) | 0 | 0 | 0 | 0.0 |
| DP3 (Uni3D+LN) | 86 | 60 | 48 | 64.7 |
Mitigating Overfitting via 3D Data Augmentation
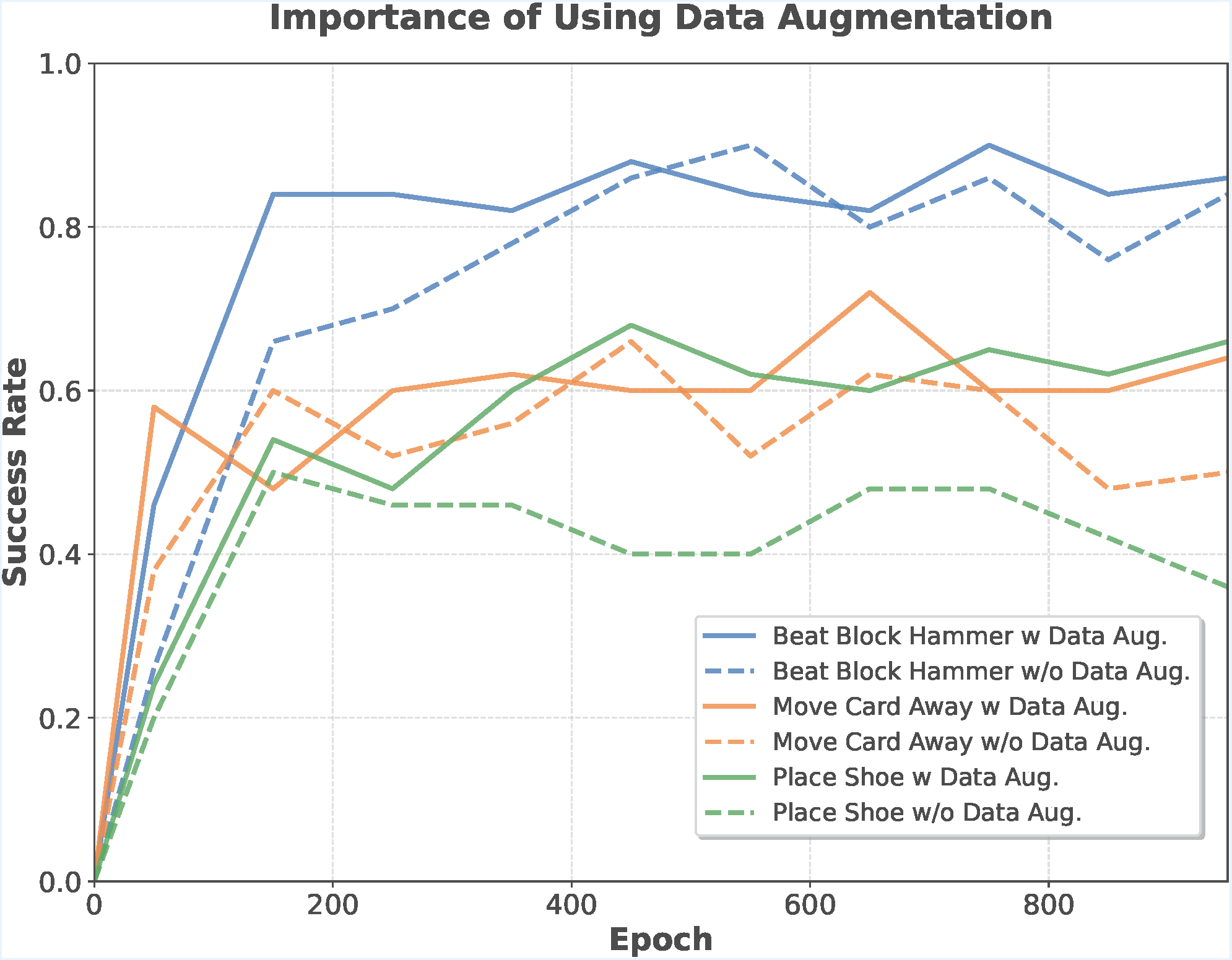
Without augmentation, success rates decline as training progresses. Our pipeline stabilizes training and significantly boosts generalization.
3D policy training is prone to overfitting. We introduce a three-part augmentation pipeline:
1
FPS Randomization
Randomize point order each step to prevent over-reliance on deterministic sampling order.
2
Color Jitter
Random brightness, contrast, and saturation variations on RGB channels of the point cloud.
3
Noise & Dropout
Gaussian noise on coordinates and proprioception, plus random point dropout for robustness to incomplete inputs.